MLIR-ARX: Accelerator-Aware MLIR-to-RISC-V Compilation Integrated with an EDA Flow
TLDR
Heterogeneous RISC-V systems challenge us to keep model representations coherent while deciding what to accelerate as hardware evolves. mlir-arx treats MLIR as a unifying representation layer: we introduce an arx dialect that encodes accelerator capabilities, inject lightweight profiling ops, and use a two-stage (analytic + profile-guided) cost model to form maximal offload regions under resource and dependency constraints. By aligning model computations across CPU and accelerators in a single IR space, our compile–-measure loop reliably selects profitable regions and delivers substantial end-to-end speedups on a MNIST CNN with a configurable VTA overlay on a Genesis FPGA prototype.
Availability. Source code and artifacts are available at: Repository in Our Gitlab
1. Introduction
Edge and embedded AI systems increasingly pair general-purpose RISC-V cores with domain accelerators (from NPUs to lightweight tensor engines) to meet stringent latency and energy targets
MLIR’s multi-dialect design and progressive lowering are a natural fit for this workflow
1.1 Requires
- IR-level capability modeling to express an accelerator’s constraints
- lightweight profiling instrumentation that can be injected/stripped by passes
- a cost model that joins analytic estimates with profile-derived efficiencies
- packaging that integrates with an SoC/EDA flow.
We present MLIR-ARX, a profile-guided compiler built on MLIR that introduces an arx dialect for accelerator capabilities, selects profitable offload regions via a two-stage cost model, and provides a retargetable backend integrated with RISC-V eXpressRVX) for FPGA bring-up
1.2 Contributions
- Accelerator-aware IR. An
arxdialect that captures accelerator capabilities (constraints, tiling, resource usage) and enables principled lifting of standard tensor ops. - Cost-guided partitioning. A two-stage (analytic + profile-guided) model that forms offload regions with explicit DMA orchestration and safe CPU fallbacks.
- Retargetable backend + RVX integration. Code generation for RISC-V plus accelerator stubs and a device manifest that RVX uses for automatic integration.
- Early evaluation. A small CNN on MNIST running on RVX-based FPGA prototypes with VTA, validating the compile–measure loop and selection mechanism.
2. Background
MLIR Foundations and Target Platform
2.1 MLIR in brief
MLIR is a multi-level compiler infrastructure that represents computations at various abstraction levels and supports progressive lowering through dialects and pattern-based rewritesMLIR-ARX include mhlo/StableHLO for tensor semanticslinalg for structured kernels, and memref for explicit memory.
Two features are central to our setting: bufferization, which separates algorithmic transformations from storage decisions by converting tensors to memrefs with explicit lifetimes, and dialect interfaces/converters, which allow capability-aware lifting or lowering between dialects. These make it possible to express accelerator constraints in IR and offload only the supported regions. Prior systems, from TVM’s multi-backend flow
2.2 Why MLIR for RISC-V + Accelerators
RISC-V-based edge platforms often combine a control processor (with or without a vector extension) and one or more domain accelerators attached via a memory-mapped interconnect.
This creates three immediate needs:
- partitioning of the model into CPU and accelerator regions.
- explicit orchestration of DMA, synchronization, and address spaces.
- graceful fallback when constraints are violated. MLIR’s dialect modularity lets us.
(a) express accelerator capabilities as IR-level contracts, (b) form and legalize offload regions under those contracts, and (c) lower both sides—CPU and accelerator stubs—within a single pass manager, sharing analyses (shape, alias, dependence) across the boundary. Compared with ad-hoc code generators, the benefits are: reuse of upstream transformations, uniform debuggability, and a single IR for both accelerated and non-accelerated builds.
2.3 RVX overview
RVX is an EDA environment to assemble RISC-V SoCs (single-/multi-core, memory subsystem, interconnect, peripheral IP), validate them on FPGA, and produce handoff artifacts for siliconMLIR-ARX targets this boundary: it emits CPU binaries, an accelerator runtime and driver stubs, and a device manifest that RVX consumes to wire up interconnect ports and firmware tables. By aligning compiler outputs with RVX’s manifests, we avoid manual bring-up steps when retargeting cores or adding/removing accelerators.
We primarily target edge-style RISC-V SoCs where accelerators are memory-mapped with local SRAM and DMA engines. Our current prototype assumes statically known shapes in offload regions; dynamic-shape support is under active development.
3. Design and Architecture
Profile-Guided MLIR-to-RISC-V Offload
3.1 Pipeline Overview
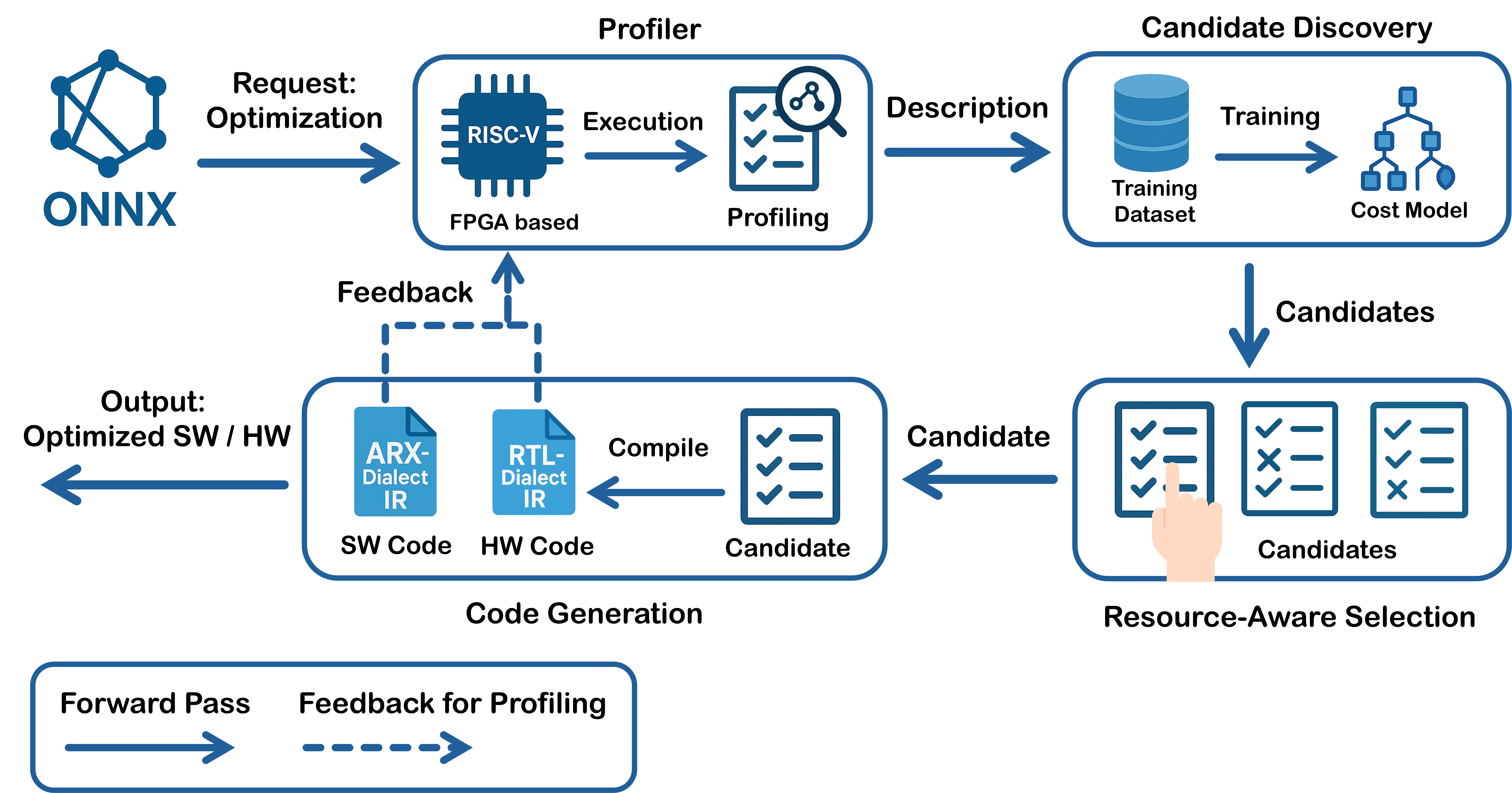
Figure 1 shows the end-to-end flow: models import into MLIR, run once on a CPU baseline to profile, mine offload candidates, select them under FPGA budgets, form offload regions, and lower to CPU and accelerator backends. A machine-readable accelerator description generates the arx dialect and converters; RVX profiling closes the compile–measure loop.
3.2 Baseline Execution and Profiling
MLIR-ARX assumes no accelerator a priori. Every model first executes end-to-end on RISC-V, producing per-op/region profiles (cycles, bytes moved, stalls, shapes/dtypes/layouts) keyed by stable IR handles. This path is also the correctness fallback for any region that proves illegal or unprofitable to offload.
3.3 Candidate Discovery and Cost Modeling
Hot single ops or short fusable patterns are grouped by semantics/constraints as offload candidates. For a region $R$, we use an inline estimate $\Delta T(R)=T_{\mathrm{cpu}}(R)-T_{\mathrm{off}}(R)$ with $T_{\mathrm{off}}\approx T_{\mathrm{setup}}+\max(T_{\mathrm{dma}},T_{\mathrm{cmp}})+T_{\mathrm{sync}}$ where analytic terms (op counts, tiling, bandwidth/latency) are corrected by profile-derived efficiencies.
3.4 Resource-Aware Selection and Partitioning
On FPGA targets, selection respects LUT/FF/DSP/BRAM, local SRAM, DMA lanes, and clock budgets. Given per-candidate resource costs $\mathcal{R}(c)$ and budget $B$, we maximize $\sum\Delta T(c)$ subject to $\sum\mathcal{R}(c)\le B$, preferring high benefit density when tight. Selected ops become maximal \emph{offload regions} under dependency/memory constraints; the compiler inserts explicit host–device copies/fences and schedules DMA to overlap with compute.
3.5 Lowering and Runtime
Both CPU and accelerator paths first lower into the arx dialect. CPU ops then follow linalg $\to$ scf/affine $\to$ LLVM to produce RISC-V ELFs, while accelerator ops lower directly to library calls with a thin runtime and DMA descriptors. A device manifest (MMIO ranges, IRQ lines) is also emitted for RVX integration.
3.6 Retargeting and feedback
A YAML/JSON accelerator description regenerates the arx capability model and converters, enabling recompilation without model changes. Deployed binaries feed fresh RVX profiles back into the cost model, which updates efficiencies and re-ranks candidates for the next iteration.
4. Implementation
ONNX-MLIR Base, ARX Dialect, and RVX/VTA Bring-up
4.1 Codebase and MLIR Integration
We implement MLIR-ARX by extending the open-source ONNX-MLIRARX components. The output code runs unmodified on RVX-synthesized RISC-V platforms; when no accelerator is present, the CPU path serves as the numerically correct fallback.
4.2 ARX Dialect and Lowering Paths
The arx dialect lifts eligible tensor and linalg ops into accelerator-aware form, annotated with capability and tiling metadata. Both CPU and accelerator ops lower through this dialect: CPU paths continue via linalg $\to$ scf/affine $\to$ LLVM for RISC-V binaries, while accelerator ops become driver/library calls with explicit host–device transfers. Because both paths share the same pass pipeline, analyses such as shape, aliasing, and dependence are reused across CPU and accelerator lowering.
4.3 Profiling Instrumentation
To support the profile-driven flow, we define lightweight profiling ops (begin/end counters, byte/traffic counters, DMA/compute timestamps). When the compiler is invoked with a profiling option, an instrumentation pass inserts these ops around selected regions/ops during canonicalization and bufferization. The pass is designed to be idempotent and can be stripped in a late “de-instrumentation” pass for production builds. Profiles are keyed by stable IR handles to survive recompilation unless shapes change.
4.4 Accelerator Target: VTA
For an initial hardware target we use Apache TVM’s VTA soft accelerator. VTA implements a small set of tensor primitives with parameterizable compute parallelism (e.g., PE width), local SRAM sizes, and instruction buffer depth. This configurability makes it a good vehicle to test MLIR-ARX’s candidate selection and resource-aware partitioning: The capability model is regenerated from the chosen VTA configuration, while the cost model estimates tile fit, DMA overlap, and achievable throughput under the given SRAM and bandwidth constraints.
5. Early Evaluation
5.1 Setup
Our prototype system follows the dual-ORCA configuration in prior TIP work, with two ORCA RISC-V RV32IM cores synthesized at 100 MHz on a Genesis FPGA and connected via the RVX-generated $\mu$NoC and AXI-based DRAM subsystem. A configurable VTA overlay is attached as an MMIO+DMA device, using 8-bit inputs/weights, 32-bit accumulators, and a $16{\times}16{\times}16$ GEMM block. All components are generated by RVX from a manifest and deployed to FPGA.
5.2 Benchmark
For evaluation, we use a small CNN for MNIST consisting of two conv+ReLU blocks with $2{\times}2$ pooling, followed by a fully connected layer (input $1{\times}28{\times}28$). Profiles are first collected from the CPU-only execution to guide candidate discovery. Operators selected for offload are conv2d(+bn)+relu blocks (Conv1, Conv2) and the final fully connected layer; control flow, quantize/dequantize, and maxpool remain on the CPU.
5.3 CPU-only Baseline
Table 1 reports the measured per-layer latency on the dual ORCA cores. The two convolution layers dominate the runtime (over 95 % of total latency), making them the primary candidates for acceleration.
5.4 Projected Accelerator Performance
Since the FPGA prototype is still under integration, we estimate accelerator-side performance using a simple throughput model assuming three VTA configurations (A/B/C) with 256/512/1024 MAC/cycle. Table 1 shows the projected latency when Conv1, Conv2, and the fully connected layer are offloaded to VTA, while other layers remain on the CPU. The results indicate a potential end-to-end speedup of $50 \times$–$90\times$ compared to the CPU-only baseline, with hardware resource utilization scaling from $\sim$ 15 % to $\sim$ 60 % of available DSPs on the target FPGA.
| Layer | Ops | CPU-only (µs) | VTA-A (µs) | VTA-B (µs) | VTA-C (µs) |
|---|---|---|---|---|---|
| 1. Quantize | — | 5.73 | — | — | — |
| 2. Conv1 | 97,344 | 884.20 | 5.07 | 2.54 | 1.27 |
| 3. MaxPool1 | 10,816 | 28.96 | — | — | — |
| 4. Conv2 | 557,568 | 2949.15 | 29.04 | 14.52 | 7.26 |
| 5. FullyConnected | 5,120 | 4.76 | 0.27 | 0.13 | 0.07 |
| 6. Dequantize | — | 0.50 | — | — | — |
| Total | 670,848 | 3873.30 | 69.57 | 52.38 | 43.78 |
| HW Util. (DSP / BRAM / LUT %) | — | 15 / 44 / 12 | 31 / 44 / 21 | 61 / 46 / 36 | |
6. Conclusion
We presented MLIR-ARX, a profile-driven MLIR compiler that begins from a CPU-only RISC-V baseline, identifies profitable regions, and offloads them to accelerators under resource and orchestration constraints. MLIR-ARX introduces the arx dialect for capability-aware lifting, lightweight profiling instrumentation, and a retargetable backend integrated with RVX. Early evaluation on a small MNIST CNN with a configurable VTA overlay shows that offloading Conv1/Conv2/FC achieves order-of-magnitude latency reductions over the dual-ORCA CPU baseline, consistent with our cost-model predictions.
7. Limitations and outlook
Our cost model is analytic with profile-derived corrections; learned models may better capture controller effects and DMA/compute overlap. Offload regions currently assume static shapes; extending legality/bufferization for dynamic-shape cases is ongoing. Finally, while the CPU path can exploit vector intrinsics, full scheduling for attention-like blocks and multi-accelerator concurrency remains future work. We expect these extensions—alongside broader accelerator backends—to further tighten the compile–measure loop and reduce manual retargeting on RVX platforms.
8. Related Work
RISC-V CPUs, Vector Extensions, AI Accelerators, and Design Space Exploration
8.1 RISC-V as the Control Plane for Heterogeneous ML SoCs
Open RISC-V implementations range from tiny in-order microcontrollers to out-of-order Linux-class cores, making them a natural control plane for accelerator-rich SoCs. Representative open cores include Rocket (in-order) and BOOM (out-of-order) from the Berkeley stack
8.2 RISC-V Vector and Packed-SIMD for ML
The RISC-V Vector extension (RVV)
8.3 Attachment Patterns for AI Accelerators
Three patterns dominate:
-
Memory-mapped DMA engines: accelerators with local SRAM and DMA, controlled as MMIO devices; the most common in embedded contexts.
-
Coprocessors (e.g., RoCC): accelerators invoked via custom instructions or queues, reducing software overhead but tying the ABI to a core design
. -
Streaming/NoC-attached engines: connected via on-chip networks with stream interfaces; the host sets up dataflow graphs and dispatches jobs.
MLIR-ARX assumes the first pattern (MMIO+DMA) but its IR contracts generalize to other attachments.
8.4 Tensor Accelerators and Dataflows
A wide body of work covers compute/dataflow design for DNNs: systolic arrays (e.g., TPU
8.5 FPGA Overlays and Soft Accelerators
FPGAs serve as prototyping and deployment platforms for edge ML accelerators. Overlay designs, including VTA
8.6 Memory Systems and Data Movement
Memory hierarchy decisions strongly influence performance and energy. Designs like Eyeriss exploit row-stationary mapping to minimize off-chip traffic; others (e.g., MAERI, SCNN) adapt to sparsity and flexible reductions. For RISC-V-attached accelerators, key challenges are software-visible packing/tiling to match SRAM/DMA configurations and overlapping DMA with compute. MLIR-ARX’s ARX dialect makes these constraints explicit in IR.
8.7 Design Space Exploration (DSE) for AI Accelerators
DSE methods co-optimize accelerator architecture and mapping. Frameworks like ZigZag
These DSE strategies are applicable to RISC-V–integrated accelerators, where FPGA/SoC constraints require balancing performance and resource use. In MLIR-ARX, the cost model and candidate selection can be extended to search over accelerator microarchitectures and RISC-V/accelerator interface options, further tightening the compile–measure loop.
8.8 Positioning of MLIR-ARX
MLIR-ARX complements the hardware and DSE work above by embedding accelerator capability models in IR, using profile-guided cost modeling to identify profitable offloads, inserting legal DMA/synchronization with overlap, and retargeting automatically to new accelerators or configurations without model changes. Hardware advances supply the building blocks; MLIR-ARX provides the IR-level integration and automation in a RISC-V EDA flow.
8.9 MLIR-centric compiler stacks and HLS/RTL generation
MLIR has increasingly been used not only as a software-oriented IR but also as a hardware-construction and HLS coordination layer. The CIRCT project extends MLIR with hardware-facing dialects (e.g., hw, comb, sv, fsm) and export passes to synthesizable SystemVerilog, enabling end-to-end generation of RTL directly from MLIR programs handshake and staticlogic dialects capture fine- and coarse-grain control and enable automated scheduling/retiming before \emph{ExportVerilog}. These flows complement software-oriented tensor dialects by giving a path to hardware under the same abstraction umbrella.
A second line of work connects MLIR to C/C++ code generation as an HLS front end. The EmitC path lowers structured MLIR to portable C++ suitable for downstream toolchains, including HLS compilers, while preserving shape and buffer semantics. Building on this idea, ScaleHLS uses MLIR to drive loop transformations (tiling, unrolling, pipelining) and memory partitioning so that the emitted C/C++ attains predictable quality-of-results when synthesized by commercial HLS tools
Dynamic and elastic dataflow HLS has also been explored atop MLIR. Dynamatic integrates with MLIR’s handshake pipeline to generate elastic circuits that tolerate variable-latency operators and memory, bringing modulo scheduling and token-based control to the HLS space
Position relative to our system. These efforts show two practical integration patterns for MLIR: (i) MLIR $\to$ RTL via CIRCT-style dialects, and (ii) MLIR $\to$ C/C++ via EmitC/ScaleHLS for HLS back ends. MLIR-ARX currently focuses on partitioning and orchestrating offload regions under a unified IR for CPU and accelerator execution, but its capability model and region formation are compatible with both patterns: the same arx ops can be lowered either to MMIO-driven stubs (our VTA/RVX path) or, in a future backend, to HLS-friendly C++ or directly to RTL through CIRCT. This suggests a path to automatically synthesize specialized accelerators for hot regions discovered by the profile-guided flow, while preserving the CPU fallback and the EDA integration boundary already in place.
9. VTA Configuration and Expected Performance on FPGA
9.1 Hardware overview
VTA is a soft deep-learning accelerator intended for FPGAs. It implements a decoupled three-stage pipeline (load, compute, store) with dedicated on-chip buffers and task queues, enabling overlap of DMA and compute when tiling admits double buffering
9.2 Configuration reported on ZCU102
As background, we refer to the ZCU102-oriented VTA configuration summarized in Table 2, reported by prior work
| Attribute | JSON (log2) | Interpreted value | Effect |
|---|---|---|---|
LOG_INP_WIDTH | 3 | 8-bit int | input precision |
LOG_WGT_WIDTH | 3 | 8-bit int | weight precision |
LOG_ACC_WIDTH | 5 | 32-bit int | accumulator precision |
LOG_BATCH | 0 | 1 | batch factor in intrinsic |
LOG_BLOCK | 4 | 16 | inner GEMM tile (PE block) |
LOG_UOP_BUFF_SIZE | 16 | 64 KiB | micro-op buffer |
LOG_INP_BUFF_SIZE | 16 | 64 KiB | input buffer |
LOG_WGT_BUFF_SIZE | 19 | 512 KiB | weight buffer |
LOG_ACC_BUFF_SIZE | 18 | 256 KiB | accumulator buffer |
9.3 Implications for tiling and overlap
Given LOG_BLOCK=4, the intrinsic compute block is $16{\times}16{\times}16$.
Legal tiles must satisfy buffer capacity and alignment constraints for the three-stage pipeline:
(i) an input/weight sub-tile that fits {64 KiB, 512 KiB} with layout-specific padding. (ii) an accumulator tile that fits 256 KiB. (iii) DMA chunking that aligns with the memory interface.
When these constraints are met, double buffering allows:
\[T_{\mathrm{off}}\approx T_{\mathrm{setup}}+\max(T_{\mathrm{dma}},T_{\mathrm{cmp}})+T_{\mathrm{sync}},\]and hides the smaller of DMA/compute times.
9.4 Mapping to MLIR-ARX
In mlir-arx’s YAML capability description, the configuration in Table 2 becomes the static part of the accelerator model (precision, intrinsic block, buffer capacities). The partitioner only lifts regions whose tiles provably fit, and the cost model accounts for (i) the $\max(T_{\mathrm{dma}},T_{\mathrm{cmp}})$ overlap enabled by double buffering, (ii) setup/synchronization, and (iii) memory-traffic inflation from packing and padding. Under multi-VTA, the resource model exposes the number of instances and the shared DRAM bandwidth so that selection can avoid overcommitting the memory system.
10. ARX Dialect
Selected Operations and Capability Schema
This section sketches the subset of ARX operations and attributes that our prototype uses to plan and legalize offload regions. The design mirrors MLIR’s convention of making capabilities explicit at IR boundaries so that legality and code generation are mechanically checkable.
10.1 Core ops and attributes
Table 3 summarizes representative ops and their key attributes. The attributes are chosen so that (i) legality checks are local, (ii) tiling constraints can be statically validated, and (iii) DMA and compute costs can be derived from sizes and layouts.
| Op | Key attributes | Notes |
|---|---|---|
arx.conv2d | dtype, strides, dilations, padding, tile_h, tile_w, ic_blk, oc_blk | Convolution lifted from linalg.conv_*. Tiling attributes reflect scratchpad fit and inner GEMM blocking. |
arx.gemm | dtype, M_blk, N_blk, K_blk | Canonicalized matmul; blocks must be multiples of the accelerator's intrinsic block. |
arx.pool | mode, kH, kW, strides | Optional; emitted only when the accelerator implements pooling. |
arx.copy | src_space, dst_space, bytes, align | Logical copies across host/device address spaces. Lowered to DMA descriptors when possible. |
arx.region | reads, writes, sram_bytes | Opaque offload region container; captures side conditions (aliasing, fences). |
10.2 Example lifting
A legal linalg.matmul with shapes that fit the intrinsic block becomes:
%y = arx.gemm %a, %b
{ dtype = i8, M_blk = 16, N_blk = 16, K_blk = 16 } : ...
11. Profiling Instrumentation and Log Schema
11.1 Instrumentation ops
Profiling is injected by a dedicated pass when a command-line flag is set. The ops are intentionally minimal so that they can be stripped late in the pipeline.
arx.prof.begin handle: i64 {counters = [cycles, bytes_rd, bytes_wr]}arx.prof.end handle: i64
The pass places begin/end around candidate ops and region boundaries after bufferization, ensuring that the measured bytes reflect concrete memref layouts and copies.
11.2 Runtime counters and emission
On RVX, the runtime reads CPU cycle counters and DMA byte counters at begin/end. Each record is keyed by the IR handle (a stable 64-bit hash).
record {
handle: 0x17a3...
cycles: 239812
bytes_rd: 1572864
bytes_wr: 262144
stalls: {dma_wait: 0.12, sram_bank: 0.03}
}
In instrumented CPU-only builds, median overhead was about 2.1% on MNIST-sized graphs (illustrative; replace with measured values in Table 1).
12. Cost Model Details and Selection Algorithm
12.1 Timing model
For a region $R$ with tiled compute and double buffering:
\[T_{\mathrm{off}}(R) \approx T_{\mathrm{setup}} + \max\!\big(T_{\mathrm{dma}}(R), T_{\mathrm{cmp}}(R)\big) + T_{\mathrm{sync}}.\]DMA time uses transferred bytes and effective bandwidth $B_{\mathrm{dma}}$, including packing/padding inflation $\rho \ge 1$:
\[T_{\mathrm{dma}}(R) = \frac{\rho\cdot(\mathrm{bytes}_{\mathrm{in}}+\mathrm{bytes}_{\mathrm{out}})}{B_{\mathrm{dma}}}.\]Compute time is derived from MAC counts divided by peak MAC/s and corrected by a profile-derived efficiency $\eta\in(0,1]$:
\[T_{\mathrm{cmp}}(R) = \frac{\mathrm{MACs}(R)}{\eta\cdot P_{\mathrm{peak}}}.\]The net benefit is $\Delta T(R) = T_{\mathrm{cpu}}(R) - T_{\mathrm{off}}(R)$.
12.2 Resource model
Each candidate $c$ has a resource vector $\mathcal{R}(c)$ over {LUT, FF, DSP, BRAM, SRAM, DMA lanes}. Selection maximizes $\sum \Delta T(c)$ subject to $\sum \mathcal{R}(c) \le B$ with a benefit-density tie-breaker when budgets are tight.
12.3 Region formation
Candidates are merged greedily into maximal regions when:
- data dependencies allow reordering or fusion,
- the merged tile still fits on-chip buffers, and
- the merged cost is superadditive after accounting for fewer host–device crossings.
13. MNIST Model Shapes and Mapping Notes
For reproducibility and debugging, Table 4 lists the operator shapes used in the early evaluation.
| Op | Input shape | Weight shape | Output shape | Tile selection |
|---|---|---|---|---|
| conv1 | 1×1×28×28 | 16×1×3×3 | 1×16×26×26 | M=16, N=16, K=16 blocks |
| conv2 | 1×16×13×13 | 32×16×3×3 | 1×32×11×11 | same as above |
| gemm | 1×512 | 512×10 | 1×10 | M=16, N=16, K=16 with packing |
Acknowledgments
This work was supported by the Institute of Information \& Communications Technology Planning \& Evaluation (IITP)grant funded by the Korea government (MSIT) (No.RS-2024-00459797, No.RS-2023-00277060, No.RS-2025-02217404, No.RS-2025-02214497, No.RS-2025-02216517)